难度:⭐
题目描述:
给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。
返回该 最大总和 。
示例1:
1 | 输入:nums = [1,4,3,2] |
示例2:
1 | 输入:nums = [6,2,6,5,1,2] |
提示:
1 <= n <= 10^4nums.length == 2 * n-10^4 <= nums[i] <= 10^4
解题过程:
思路:
题目就是要把数组中的元素两两分组,尽量使每一组的最小值大一些,思考怎么分组?
其实就是把数组中的两个最小值分到一起,然后对剩下的元素也是挑选最小的两个值分组。
既然这样,只要对数组进行升序排序,然后累加偶数位置的元素值返回就好了。
c++代码:(执行用时168ms,击败46.71%,内存消耗27.8M,击败18.66%)
1 | class Solution { |
官方题解:
方法一 暴力求解 [超过时间限制]
算法
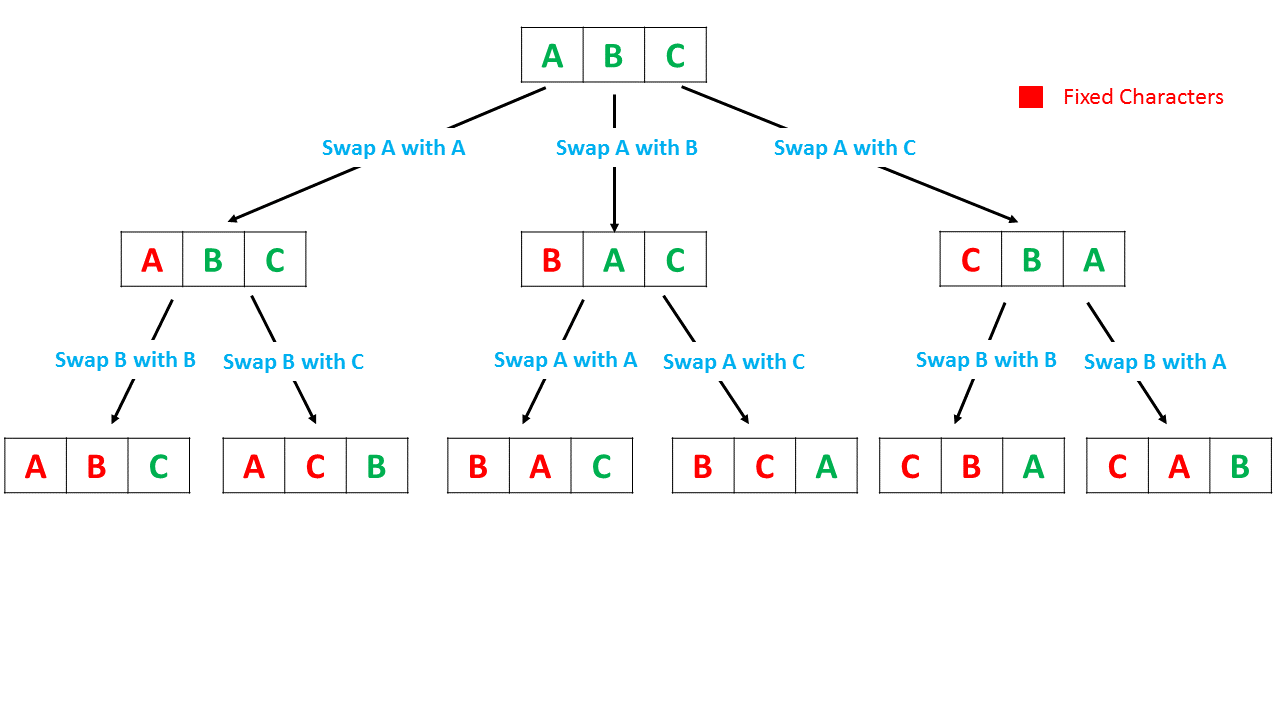
最简单的解决方案是考虑 $nums$ 数组的元素每个可能的配对集。为了生成所有可能的配对,我们使用函数 permute(nums,current_index)。此函数创建给定数组元素的所有可能排列。
为此,permute将当前元素 current_index的索引作为参数之一,然后,它将当前元素与数组中的每个其他元素交换,向右移动,以便生成数组元素的新排序。在完成交换之后,它再次调用 permute,但这次使用数组中下一个元素的索引。返回时,我们反转当前函数调用中的交换。
因此,当到达数组的末尾时,会生成数组元素的新排序。考虑配对的元素,使得每对的第一个元素来自新数组的前半部分,第二个元素来自数组的后半部分。因此,我们总结了所有这些可能配对中的最小元素,并找出它们的最大总和。
下面的动画描述了排列的生成方式。
Java代码:
1 | public class Solution { |
复杂度分析
时间复杂度:$O(n!)$。对于数组中的 $n$ 元素,总共可以 $n$ 排列。
空间复杂度:$O(1)$。仅需使用常数级的额外空间。
方法二 排序 [通过]
算法
为了理解这种方法,让我们从不同的角度来看待问题。我们需要形成数组元素的配对,使得这种配对中最小的总和最大。因此,我们可以查看选择配对中最小值的操作,比如 $(a,b)$ 可能会产生的最大损失 $a-b$ (如果 $a > b$)。
如果这类配对产生的总损失最小化,那么总金额现在将达到最大值。只有当为配对选择的数字比数组的其他元素更接近彼此时,才有可能将每个配对中的损失最小化。
考虑到这一点,我们可以对给定数组的元素进行排序,并直接按排序顺序形成元素的配对。这将导致元素的配对,它们之间的差异最小,从而导致所需总和的最大化。
1 | public class Solution { |
复杂度分析
时间复杂度:$O\big(nlog(n)\big)$。排序需要 $O\big(nlog(n)\big)$的时间。另外会有一次数组的遍历。
空间复杂度:$O(1)$。仅仅需要常数级的空间.
方法三 使用额外的空间 [通过]
算法
这种方法在某种程度上与排序方法有关。由于给定数组中的元素范围有限 [-10000, 10000],我们可以使用 $arr$ 的哈希表,这样 $arr [i]$ 存储 $(i-10000)^ {th}$元素的出现频率。 这个减法操作可以保证这个哈希表可以能够存下范围内的所有数字。
因此,现在我们可以直接以递增的顺序遍历哈希表,而不是对数组的元素进行排序。但是,任何元素也可能在给定数组中多次出现。我们需要考虑这个因素。
为此,考虑一个例子:nums:[a,b,a,b,b,a]。这个数组的排序顺序是 nums_sorted:[a,a,a,b,b,b]。(我们实际上并没有在这种方法中对数组进行排序,但是排序的数组仅用于演示)。从前面的方法,我们知道所需的配对集是 (a,a),(a,b),(b,b)(a,a),(a,b),(b,b)。现在,我们可以看到,在选择最小元素时,$a$ 将被选择两次,$b$ 将仅被选择一次。发生这种情况是因为要选择的 $a$ 的数量已经由 $a$ 的频率确定,其余的地方将由 $b$ 填补。这是因为,为了得到正确的结果,我们需要按升序考虑元素。因此,较低的数字总是优先被添加到最终结果。
但是,如果排序的元素采用以下形式:nums_sorted:[a,a,b,b,b,b],正确的配对将是 (a,a),(b,b),(b,b) )(a,a),(b,b),(b,b))。同样,在这种情况下,所选择的$a$的数量已经预先确定,但由于 $a$ 的数量是奇数,因此它不会影响最终总和中 $b$的选择。
因此,基于上面的讨论,我们遍历哈希表 $arr$。如果当前元素出现 $req_i$ 次,并且其中一个元素与右边区域中的其他元素配对(考虑虚拟排序数组),我们考虑当前元素 $\left\lceil\frac{freq_i}{2}\right\rceil$次数以及数组中出现的下一个元素 $\left\lfloor\frac {freq_j}{2}\right\rfloor$最终总和的次数。为了传播这个左边对所选数字的影响,我们使用了一个标志 $d$。如果当前集合中有剩余元素将被再次考虑,则此标志设置为 1。在从下一组中选择元素时,会考虑已考虑的相同额外元素。
在遍历哈希表时,我们确定需要考虑每个元素的正确次数,如上所述。请注意,如果数组中不存在哈希表的当前元素,则标志 $d$ 和 $sum$保持不变。
下面的代码受到 @fallcreek的启发
1 | public class Solution { |
复杂度分析
时间复杂度:$O(n)$。需要遍历一次哈希表 $arr$。
空间复杂度:。存储一个大小为$n$哈希表 $arr$ 所需要的空间。
总结:
官方题解给出答案都是用Java实现的,看来写题解的是做Java的,哈哈哈。官方题解给出了三种解题思路,其中暴力求解不可用(超出时间限制且实现复杂),排序这种方法简洁易懂效率也不错,我用的也是这种方法。第三种方法“使用额外的空间”其实好像就是计数法,真的是不同的人不同的叫法,实现起来好像也挺复杂的,暂时没看懂也没仔细看,留作后续补充,太累了,顶不住了💔。

