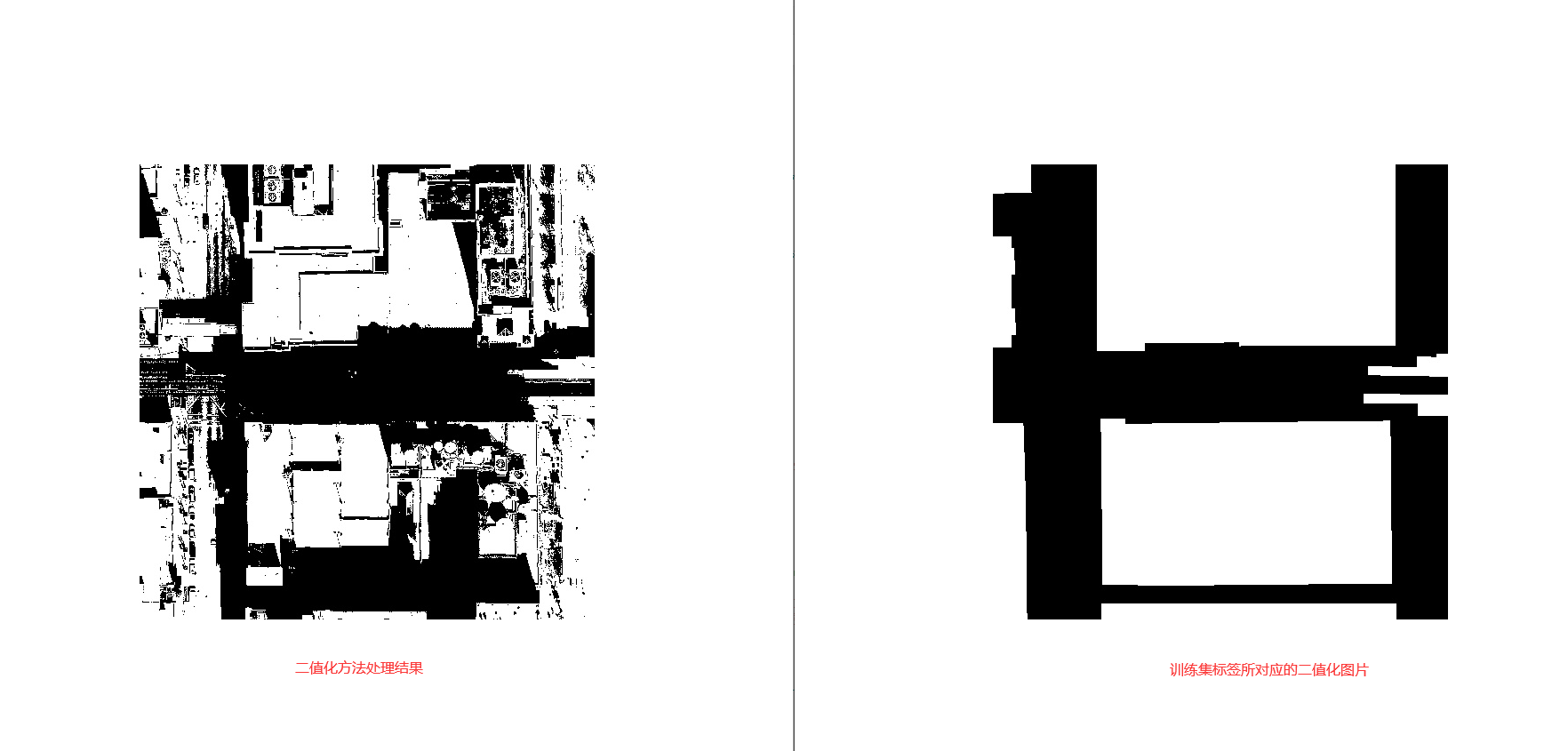
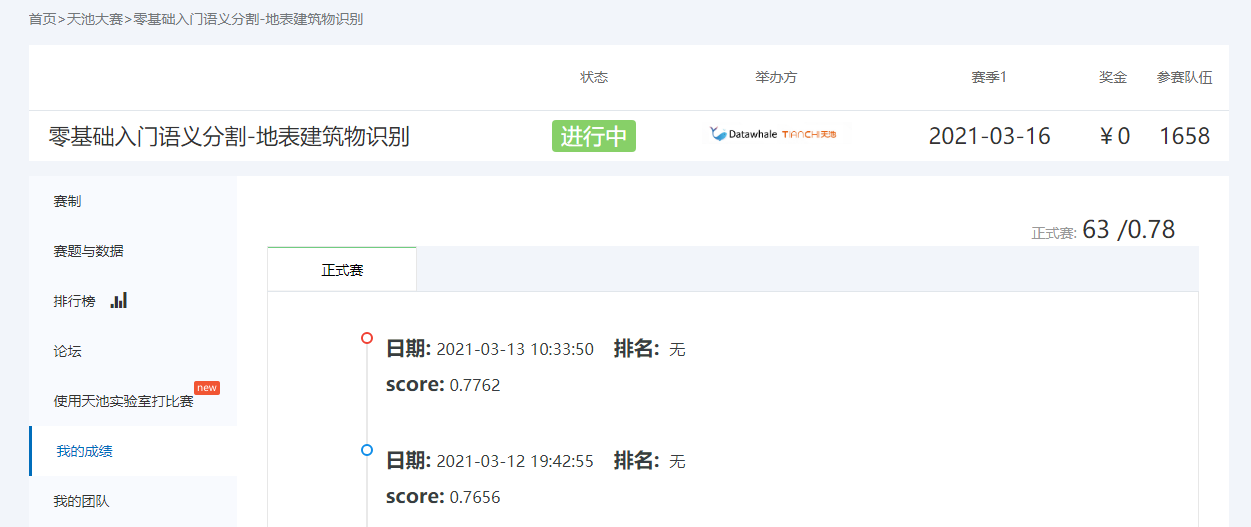
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
| import numpy as np
import pandas as pd
import pathlib, sys, os, random, time
import numba, cv2, gc
from tqdm import tqdm_notebook
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from tqdm.notebook import tqdm
# albumentations 是一个给予 OpenCV的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分割、检测)的接口,易于定制且添加其他框架非常方便
import albumentations as A
#Rasterio是基于GDAL库二次封装的更加符合Python风格的主要用于空间栅格数据处理的Python库
import rasterio
from rasterio.windows import Window
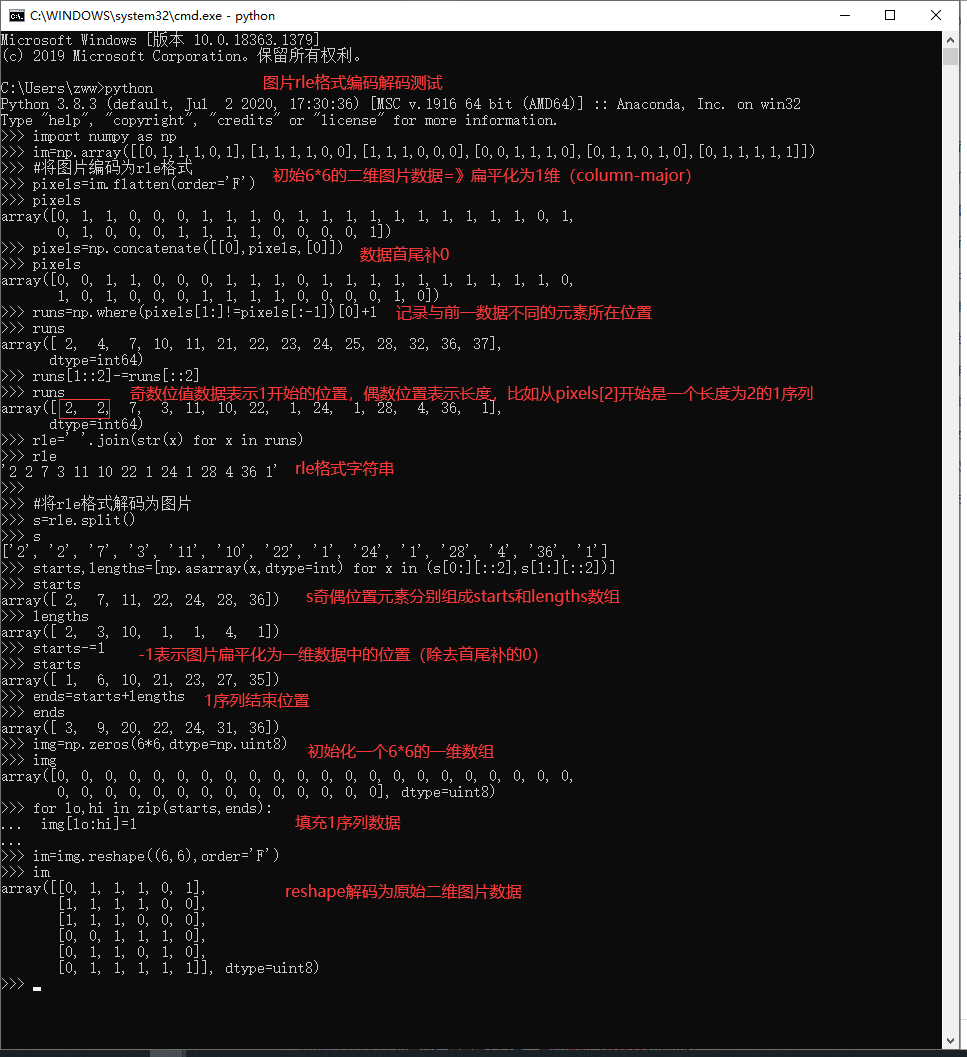
def rle_encode(im):
'''
im: numpy array, 1 - mask, 0 - background
Returns run length as string formated
'''
pixels = im.flatten(order = 'F')
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)
def rle_decode(mask_rle, shape=(512, 512)):
'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape, order='F')
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as D
import torchvision
from torchvision import transforms as T
EPOCHES = 20
BATCH_SIZE = 16
# BATCH_SIZE = 32
IMAGE_SIZE = 256
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
trfm = A.Compose([
A.Resize(IMAGE_SIZE, IMAGE_SIZE),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(),
])
class TianChiDataset(D.Dataset):
def __init__(self, paths, rles, transform, test_mode=False):
self.paths = paths
self.rles = rles
self.transform = transform
self.test_mode = test_mode
self.len = len(paths)
self.as_tensor = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
# get data operation
def __getitem__(self, index):
img = cv2.imread(self.paths[index])
if not self.test_mode:
mask = rle_decode(self.rles[index])
augments = self.transform(image=img, mask=mask)
return self.as_tensor(augments['image']), augments['mask'][None]
else:
return self.as_tensor(img), ''
def __len__(self):
"""
Total number of samples in the dataset
"""
return self.len
train_mask = pd.read_csv('./train_mask.csv', sep='\t', names=['name', 'mask'])
train_mask['name'] = train_mask['name'].apply(lambda x: './train/' + x)
img = cv2.imread(train_mask['name'].iloc[0])
mask = rle_decode(train_mask['mask'].iloc[0])
print(rle_encode(mask) == train_mask['mask'].iloc[0])
dataset = TianChiDataset(
train_mask['name'].values,
train_mask['mask'].fillna('').values,
trfm, False
)
image, mask = dataset[0]
plt.figure(figsize=(16,8))
plt.subplot(121)
plt.imshow(mask[0], cmap='gray')
plt.subplot(122)
plt.imshow(image[0]);
valid_idx, train_idx = [], []
for i in range(len(dataset)):
if i % 7 == 0:
valid_idx.append(i)
# else:
elif i % 7 == 1:
train_idx.append(i)
train_ds = D.Subset(dataset, train_idx)
valid_ds = D.Subset(dataset, valid_idx)
# define training and validation data loaders
loader = D.DataLoader(
train_ds, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
vloader = D.DataLoader(
valid_ds, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
def get_model():
model = torchvision.models.segmentation.fcn_resnet50(True)
# pth = torch.load("../input/pretrain-coco-weights-pytorch/fcn_resnet50_coco-1167a1af.pth")
# for key in ["aux_classifier.0.weight", "aux_classifier.1.weight", "aux_classifier.1.bias", "aux_classifier.1.running_mean", "aux_classifier.1.running_var", "aux_classifier.1.num_batches_tracked", "aux_classifier.4.weight", "aux_classifier.4.bias"]:
# del pth[key]
model.classifier[4] = nn.Conv2d(512, 1, kernel_size=(1, 1), stride=(1, 1))
return model
@torch.no_grad()
def validation(model, loader, loss_fn):
losses = []
model.eval()
for image, target in loader:
image, target = image.to(DEVICE), target.float().to(DEVICE)
output = model(image)['out']
loss = loss_fn(output, target)
losses.append(loss.item())
return np.array(losses).mean()
model = get_model()
model.to(DEVICE);
optimizer = torch.optim.AdamW(model.parameters(),
lr=1e-4, weight_decay=1e-3)
class SoftDiceLoss(nn.Module):
def __init__(self, smooth=1., dims=(-2,-1)):
super(SoftDiceLoss, self).__init__()
self.smooth = smooth
self.dims = dims
def forward(self, x, y):
tp = (x * y).sum(self.dims)
fp = (x * (1 - y)).sum(self.dims)
fn = ((1 - x) * y).sum(self.dims)
dc = (2 * tp + self.smooth) / (2 * tp + fp + fn + self.smooth)
dc = dc.mean()
return 1 - dc
bce_fn = nn.BCEWithLogitsLoss()
dice_fn = SoftDiceLoss()
def loss_fn(y_pred, y_true):
bce = bce_fn(y_pred, y_true)
dice = dice_fn(y_pred.sigmoid(), y_true)
return 0.8*bce+ 0.2*dice
header = r'''
Train | Valid
Epoch | Loss | Loss | Time, m
'''
# Epoch metrics time
raw_line = '{:6d}' + '\u2502{:7.3f}'*2 + '\u2502{:6.2f}'
print(header)
EPOCHES = 5
best_loss = 10
for epoch in range(1, EPOCHES+1):
losses = []
start_time = time.time()
model.train()
for image, target in tqdm_notebook(loader):
image, target = image.to(DEVICE), target.float().to(DEVICE)
optimizer.zero_grad()
output = model(image)['out']
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
# print(loss.item())
vloss = validation(model, vloader, loss_fn)
print(raw_line.format(epoch, np.array(losses).mean(), vloss,
(time.time()-start_time)/60**1))
losses = []
if vloss < best_loss:
best_loss = vloss
torch.save(model.state_dict(), './model_best.pth')
trfm = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
subm = []
model.load_state_dict(torch.load("./model_best.pth"))
model.eval()
test_mask = pd.read_csv('./test_a_samplesubmit.csv', sep='\t', names=['name', 'mask'])
test_mask['name'] = test_mask['name'].apply(lambda x: './test_a/' + x)
for idx, name in enumerate(tqdm_notebook(test_mask['name'].iloc[:])):
image = cv2.imread(name)
image = trfm(image)
with torch.no_grad():
image = image.to(DEVICE)[None]
score = model(image)['out'][0][0]
score_sigmoid = score.sigmoid().cpu().numpy()
score_sigmoid = (score_sigmoid > 0.5).astype(np.uint8)
score_sigmoid = cv2.resize(score_sigmoid, (512, 512))
# break
subm.append([name.split('/')[-1], rle_encode(score_sigmoid)])
subm = pd.DataFrame(subm)
subm.to_csv('./tmp.csv', index=None, header=None, sep='\t')
plt.figure(figsize=(16,8))
plt.subplot(121)
plt.imshow(rle_decode(subm[1].fillna('').iloc[0]), cmap='gray')
plt.subplot(122)
plt.imshow(cv2.imread('./test_a/' + subm[0].iloc[0]));
|